Open Deep
Research API
A modular, multi-agency framework for building sophisticated AI-powered research systems. Autonomous agents that plan, search, scrape, rank, and synthesize — streaming cited reports in real time.
Research that thinks,
not just retrieves
The Open Deep Research API is a production-grade framework built by Luminary AI Solutions for constructing autonomous research pipelines. Unlike naive RAG systems that retrieve and paste, ODR orchestrates a multi-agent workflow that plans its own research strategy, executes targeted web searches, scrapes and ranks content, and writes — then refines — a cited analytical report.
Built for extensibility: each "Agency" is a self-contained domain module. Ship the deep research agency today; plug in a financial analysis or legal review agency tomorrow — all sharing the same core services.
From query to
cited intelligence
See it
in action
The ODR frontend is a working demonstration of the API running in production. Submit a research query and watch the multi-agent pipeline execute in real time — plan, search, scrape, write, refine, deliver.
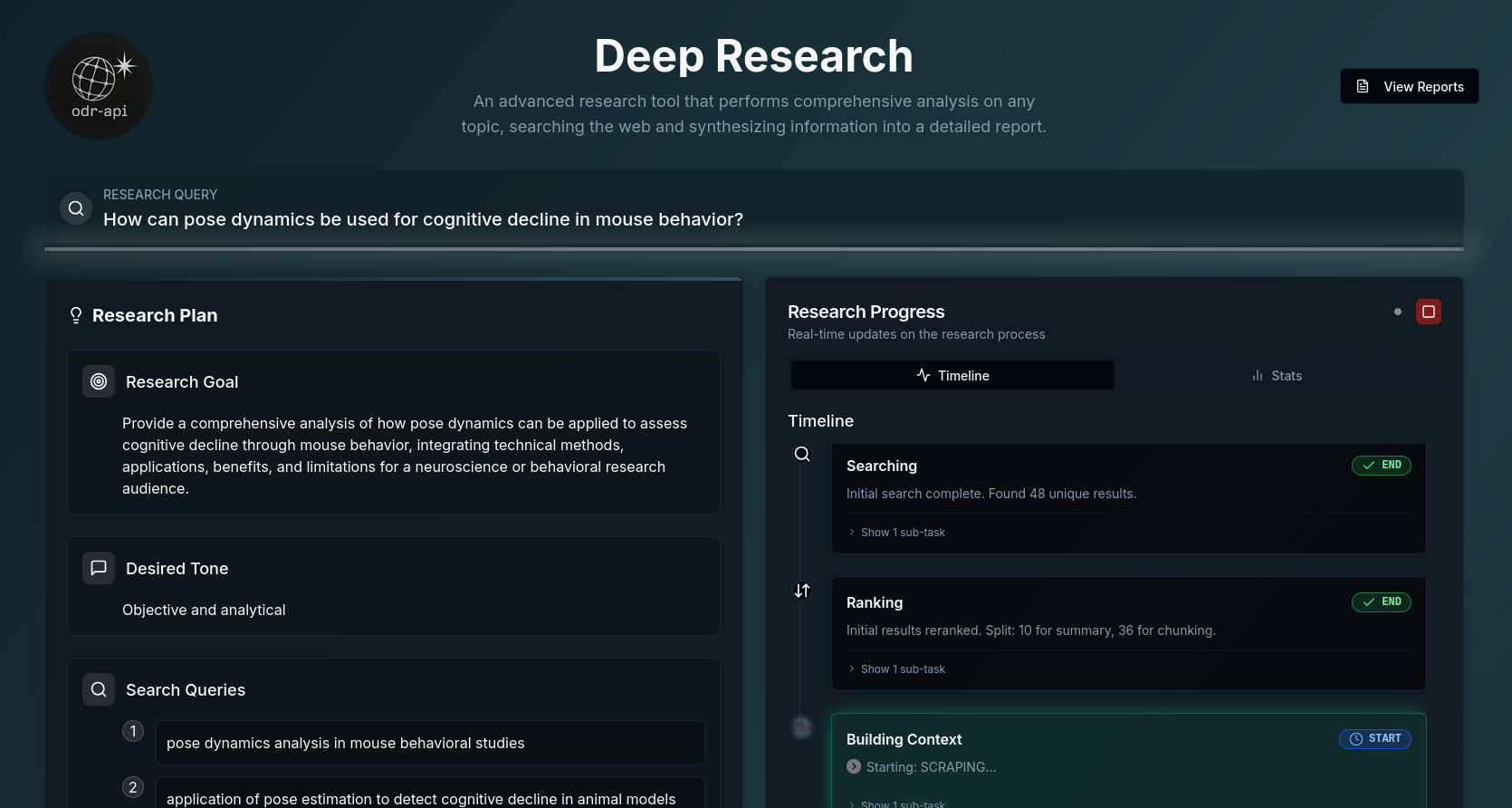
PLANNING → SEARCHING → RANKING → PROCESSING → WRITING → REFINING → COMPLETE. Clients receive live status and can render progress as it happens.Built to be
extended
ODR is our commitment to advancing the agentic research ecosystem. The architecture is deliberately designed for contribution: add a new Agency directory, define your orchestrator and agents, wire up to shared services, and you have a domain-specific research system without reinventing the wheel.
Financial analysis, legal review, competitive intelligence, scientific literature — each is a new agency. The infrastructure is already there.
View Repository# Connect and submit a research query import asyncio, websockets, json async def research(query): uri = "wss://odr.luminarysolutions.ai" uri += "/deep_research/ws/research" async with websockets.connect(uri) as ws: await ws.send(json.dumps({ "query": query, "max_search_tasks": 5 })) async for msg in ws: event = json.loads(msg) print(f"[{event['step']}] {event['message']}") if event["step"] == "COMPLETE": break asyncio.run(research("your query here"))
Where we're
pushing next
ODR is active R&D infrastructure. These are the frontiers we're actively exploring as we expand the framework toward production-grade agentic research at scale.
Build your own
research agency
ODR is production-ready infrastructure. Fork it, add your agency, and deploy a custom AI research system in days — not months. Or engage Luminary AI Solutions to build a bespoke system around your workflows.